How Policy Hidden in an Algorithm is Threatening Families in This Pennsylvania County

You hear a knock on your door. Expecting a neighbor or perhaps a delivery, you open it, only to find a child welfare worker demanding entry. It doesn’t seem like you can refuse so you let them in and watch as they search every room, rummaging through closets, drawers, cabinets, the fridge — all without a warrant. They ask questions making it sound like you’re a bad parent and, finally, say they need to do a visual inspection of your kids, undressed, without you in the room, and take pictures.
The agency receives many reports of ordinary neglect, which are distinct from physical abuse or severe neglect allegations, but it doesn’t investigate all of them. Instead, the agency had started using an algorithm to help decide who gets the knock on the door and who doesn’t. But you can’t get any information about what it said about you or your child, or how it played a role in the decision to investigate you.
Though an algorithm may sound neutral, predictive tools are designed by people. And the choices people make when creating the tool aren’t just decisions about what statistical method is better or what data is necessary to make its calculations. The same people can be flagged as more or less in need of investigation based on how a tool was designed. One recurring concern is that the use of these tools in systems marked by discriminatory treatment and outcomes will result in those outcomes being replicated. But this time, if that history repeats itself, the disparate results will be deemed unquestionable truths supported by science and math, and not the result of residual or ongoing discrimination, let alone the policy decisions that resulted when tool designers decided to choose model A instead of model B.
To better understand whether this concern is warranted, two years ago, the ACLU requested data and documents from Allegheny County, Pennsylvania related to the Allegheny Family Screening Tool (AFST) so we, together with researchers from the Human Rights Data Analysis Group, could independently evaluate its design and practical impact. We found, among other things, that the AFST could result in inequities in screen-in rates — the percentage of reports (i.e., neglect allegations received by the county child welfare agency) that are forwarded for investigation (“screened in”) out of the total number of reports received. We found that the tool could result in screen-in rate disparities between Black and non-Black families (i.e., the percentage of Black families flagged for investigation out of all allegations about Black families received could be greater than the same percentage for non-Black families). We also found that households where people with disabilities live could be labeled as higher risk than households without a disabled resident. What really stood out though was that we found the AFST’s algorithm, or the way its conclusions about a family were conveyed to a screener, could have been built in different ways that may have had a less discriminatory impact. And this alternative method didn’t change the algorithm’s “accuracy” in any meaningful way, even if we accept the tool’s developer’s definition of that term. We asked the county and tool designers for feedback on a paper describing our analysis, but never received a response. We share our findings for the first time today. But first, a quick overview of how the AFST works.
Allegheny County has been using the AFST to help screening workers decide whether to investigate or dismiss neglect allegations. (The AFST is not used to make screening decisions about physical abuse or severe neglect allegations because state law requires that those be investigated.) The tool calculates a “risk score” from 0 to 20 based on the underlying algorithm’s estimation of the likelihood that the county will, within two years, remove a child from the family involved in the report. In other words, the tool generates a prediction of the “risk” that the agency will place the child in foster care. The county and tool designers treat removal as a sign that the child may be harmed, so that the higher the likelihood of removal, the higher the score, and the greater the presumed need for child welfare intervention. Call-in screeners are instructed to consider the AFST’s output as one factor among many in deciding whether to forward the report for agency action.
However, in a child welfare system already plagued by inequities based on race, gender, income, and disability, using historical data to predict future action by the agency only serves to reinforce those disparities. And when reborn through an algorithm, people are liable to interpret the disparities as hard truths because, well, a mathematical equation told us so.
In this way, the AFST creators are doing more than math when building a tool. They also have the ability to become shadow policymakers — because unless the practical impact of their design decisions is evaluated and made public, this power can be wielded with little transparency or accountability, even though these are two of the reasons why the county adopted the tool.
Here is a summary of the design decisions and resulting policies and value judgments that we shared with the county as cause for concern:
“Risky” by Association
When Allegheny County receives a report alleging child neglect, the AFST generates an individualized “risk score” for every child in the household. However, call screeners don’t see individual-level scores. Instead, the AFST shows an output based on only the highest score of all the children in the household. For referrals where the maximum score falls between 11 and 18, the AFST displays the score’s numeric value. For maximum scores of 18 and up, the AFST displays a “High Risk Protocol” label as long as at least one child in the household is under 17. This subset of referrals is subject to mandatory investigation, which only a supervisor can override. For referrals with a maximum score less than 11 and no children under 7, screening workers see a “Low Risk Protocol” label.
We found that the decision to communicate only the AFST’s predictions of the highest-scoring child could have created inequitable outcomes. We say “could have” because we could not run our analysis on the actual numbers of Black and non-Black families so instead, as is common practice including by the county and its tool developers, we looked at Allegheny County data collected before the AFST was deployed to model what the risk scores would have been.
Compared to other ways of conveying the AFST’s scores, the method in use could have resulted in the AFST classifying Black families as having a greater need for agency scrutiny than non-Black families. Through our analysis of data from 2010-2014, we found that the AFST’s method of showing just one score would have resulted in roughly 33% of Black households being labeled “high risk,” thereby triggering the mandatory screen-in protocol, but only 20% of non-Black households would have been so labeled.
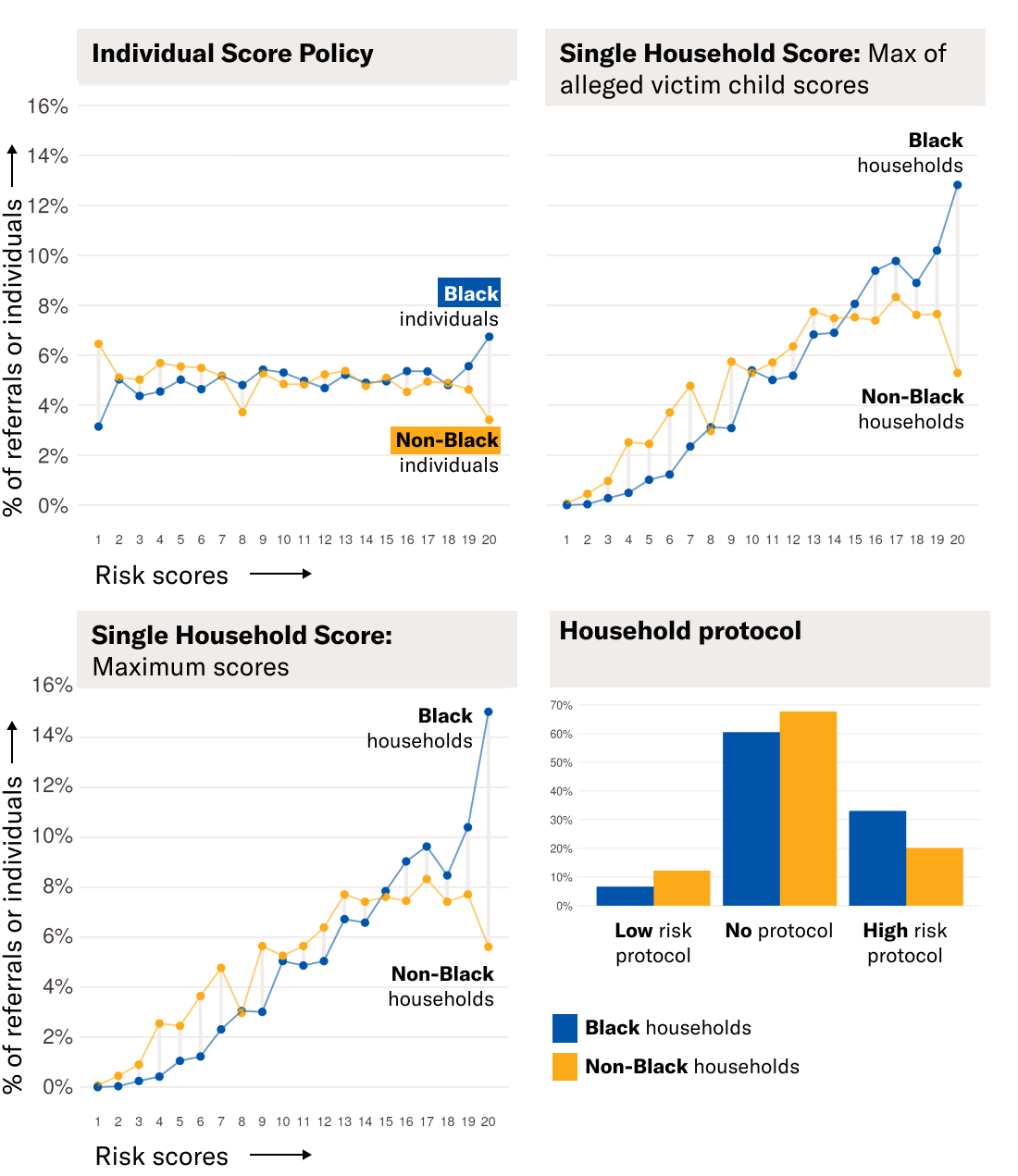
Fig. 1. Distribution of AFST Scores by Race Under Different Scoring Policies, using testing data from 2010-2014. Under policies that assign a single score or screening recommendation to the entire household, AFST scores generally increase for all families, and Black households receive the highest scores more often than non-Black households. Under the current “Single Household Score” policy, nearly 35% of Black households are labeled as “high risk” for future separation while only 20% of non-Black households are labeled as “high risk.”
The More Data, the Better?
To build the tool’s algorithm, its designers needed to look at historical records to identify circumstances and individual characteristics most associated with child removals, since the tool bases its risk scores essentially on whether and how those factors are present in the incoming report. Thus to further one of the county’s stated goals in adopting the AFST — to “make decisions [about whether to screen in a report] based on as much information as possible” — the county gave the AFST designers access to government databases beyond the county’s child welfare records, such as juvenile probation and behavioral health records. The problem is that these databases do not reflect a random sample or cross-section of the county’s population. Rather, they reflect the lives of people who have more contact with government agencies than others. As a result, using such a database to identify the characteristics of households more likely to have a child removed means selecting from a pool of factors that over-represents some groups of people and underrepresent others, making it more likely that the tool will classify the same overrepresented populations as higher risk, not because they are more likely to be harmed or to cause harm, but because the government has access to data about them but little or no access to data about others.
Take for instance the county’s juvenile probation database, which was used to construct the AFST. A recent study found that Black girls in the county were 10 times more likely and Black boys were seven times more likely than their white counterparts to end up in the juvenile justice system. As a result, in using the related juvenile probation database to build the tool, the tool developers are mining records that overrepresent Black children as compared to white children.
The behavioral health databases the county used to create the AFST are similarly problematic. Because they expressly include information about people seeking disability-related care, these databases will inevitably contain information about people with disabilities, but not necessarily others. These databases are also skewed along another axis: Because the county doesn’t record information about privately accessed health care, data about individuals with higher incomes is far less likely to be reflected.
Marked Forever
By partly basing the AFST’s removal prediction on factors that families can never change, such as whether someone has been held in the Allegheny County Jail at any time or for any reason, the AFST effectively offers families no way to escape their pasts, compounding the impacts of systemic bias in the criminal legal system. We found that households with more children are more likely to include somebody with a record in the county jail system or with HealthChoices, Allegheny’s managed care program for behavioral health services. We found that by including information that tracks whether someone has ever been associated with these systems, the AFST could have produced greater disparities in Black-white family screen-in rates than an alternate model design that did not take these factors into consideration.
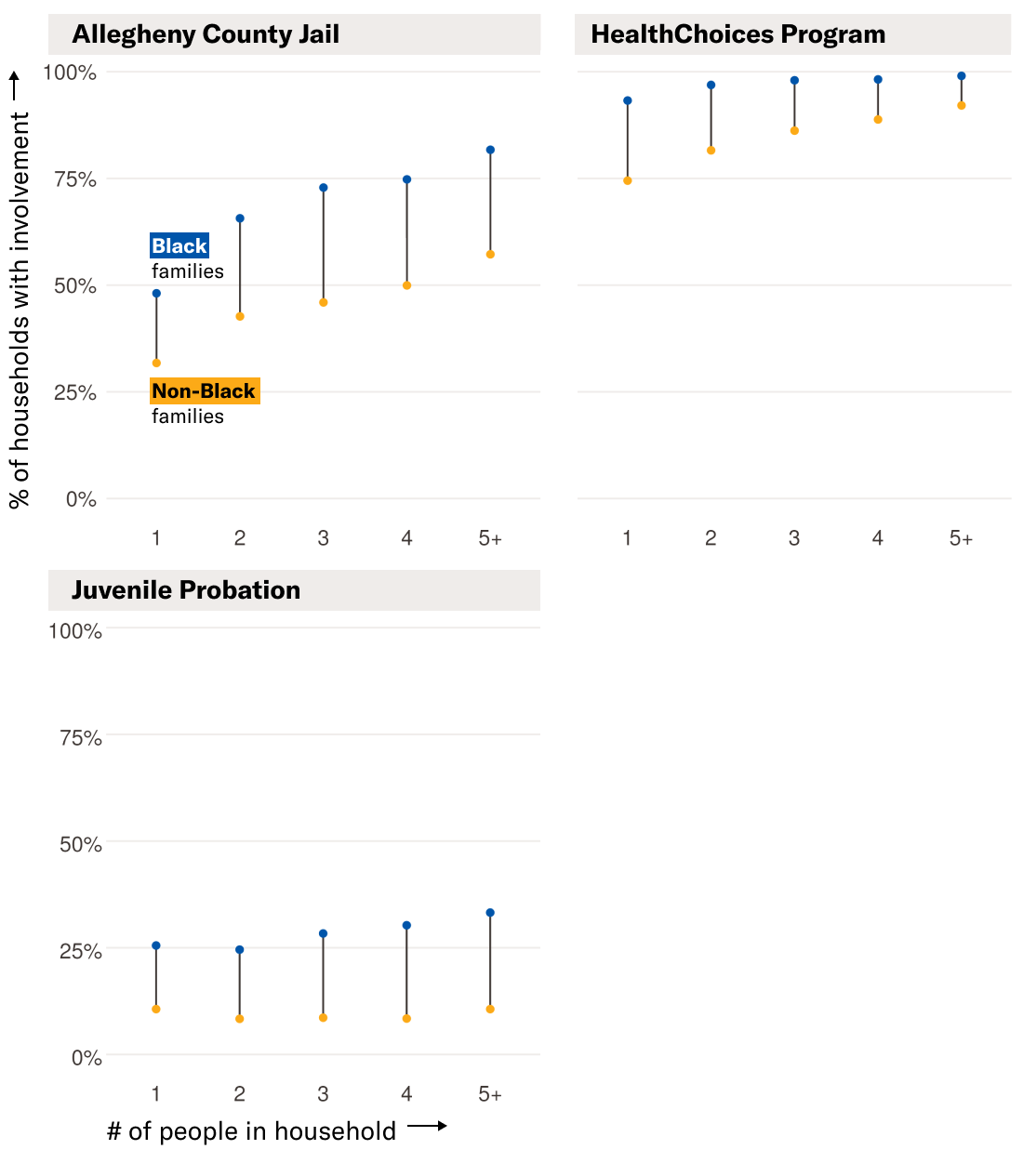
Fig. 3. As household sizes increase, the likelihood that at least one member of the household will have some history with the Allegheny County Jail, the HealthChoices program, or juvenile probation increases as well. Black households are disproportionately likely to have involvement with these systems.
Previous reporting has shown that many families do not even know the county is using the AFST, much less how it functions or how to raise concerns about it. Furthermore, government databases, from public benefits databases to criminal justice databases, are rife with errors. And what happens if the tool itself “glitches,” as has already happened to the AFST?
These challenges demonstrate the urgent need for transparency, independent oversight, and meaningful recourse when algorithms are deployed in high-stakes decision-making contexts like child welfare. Families have no knowledge of the policies embedded in the tools imposed upon them, no ability to know how the tool was used to make life-altering decisions, and are ultimately limited in their ability to fight for their civil liberties, cementing long-standing traditions of how family regulation agencies operate.
Read the full report, The Devil is in the Details: Interrogating Values Embedded in the Allegheny Family Screening Tool below:

The Devil is in the Details: Interrogating Values Embedded in the Allegheny Family Screening Tool
We're examining how algorithmic design choices function as policy decisions through an audit of the Allegheny Family Screening Tool (AFST.)
Source: American Civil Liberties Union

Donate to the ACLU
The ACLU has been at the center of nearly every major civil liberties battle in the U.S. for more than 100 years. This vital work depends on the support of ACLU members in all 50 states and beyond.
We need you with us to keep fighting — donate today.
Contributions to the ACLU are not tax deductible.
Learn More About the Issues on This Page
- Press ReleaseMar 2025

LGBTQ Rights
Women's Rights
Senate Rejects Bill Excluding Transgender Students from School SportsSenate Rejects Bill Excluding Transgender Students from School Sports
WASHINGTON - The Senate today rejected a bill attempting to amend a landmark civil rights law to exclude transgender students from nondiscrimination protections. S. 9, a version of which passed by a slim majority in the House of Representatives in January, would prohibit any school athletics program receiving federal funding from allowing transgender women and girls to participate in athletics programs designated for women and girls. The bill seeks to narrow the range of sex discrimination prohibited by laws like Title IX by defining sex “solely on a person’s reproductive biology and genetics at birth.” “As anyone paying attention to the actions of the Trump administration can tell you, this bill is simply one part of a sweeping effort to push transgender people out of public life altogether,” said Mike Zamore, National Director of Policy & Government Affairs at the ACLU. “We need more attention on actually ensuring fair and equal opportunity for all girls and women, not inflicting invasive and humiliating checks and bullying on kids to serve adults’ political purposes. We are thankful to the senators who rejected this ugly effort to codify discrimination within a historic civil rights law, and we will always fight for the freedom of all young people to be themselves at school, including on the playing field.” Federal courts have consistently found in favor of transgender student-athletes challenging state-level bans on their equal participation consistent with their gender identity, and others have likewise rejected claims that the participation of transgender student-athletes unjustly denies opportunities to cisgender women and girls. - News & CommentaryJan 2025

Women's Rights
How “Stay-or-Pay” Contracts Are Used to Abuse Immigrant WorkersHow “Stay-or-Pay” Contracts Are Used to Abuse Immigrant Workers
Shiny Lal came to the U.S. to chase the American dream, instead she found herself in an abusive employment contract that could cost her nearly $40,000. Today, we’re urging the world’s largest private dispute resolution company to stop abusing workers. - PodcastDec 2024

Human Rights
Women's Rights
ACLU Kids on How They’d Change The World with W. Kamau BellACLU Kids on How They’d Change The World with W. Kamau Bell
- Press ReleaseOct 2024
LGBTQ Rights
+2 Issues
At Supreme Court, Tennessee Seeks to Expand Reach of Dobbs to Ban Health Care for Transgender YouthAt Supreme Court, Tennessee Seeks to Expand Reach of Dobbs to Ban Health Care for Transgender Youth
WASHINGTON – In their brief defending the state’s ban on gender-affirming medical care for transgender youth, Tennessee Attorney General Jonathan Skrmetti has asked the Supreme Court to expand its ruling overturning Roe v. Wade and allow the state to target transgender people’s autonomy over their own bodies, too. In U.S. v. Skrmetti, three Tennessee transgender youth and their families are challenging a state law that prohibits medical providers from prescribing medical treatments to transgender youth, such as puberty blockers and hormone replacement therapies, that are allowed for minors who are not transgender. Represented by the American Civil Liberties Union, the ACLU of Tennessee, Lambda Legal, and Akin Gump Strauss Hauer & Feld LLP, the families argue that the ban violates their Equal Protection rights under the 14th Amendment. In the brief filed today, Tennessee relies on the Supreme Court’s 2022 ruling in Dobbs v. Jackson Whole Women’s Health in an attempt to justify its ban on gender-affirming health care for transgender people. The brief cites to Dobbs at least 10 times in sweeping arguments to justify government sex discrimination. “We’ve seen just how far extreme politicians will push to deny us our reproductive freedom, from banning abortion to threatening IVF to even threatening to put doctors in jail for providing emergency care, with deadly consequences for women’s lives,” said Jennifer Dalven, director of the ACLU’s Reproductive Freedom Project. “The same politicians who are trying to control women have now set their sights on transgender people and their families and are trying to control their bodies and lives. Allowing politicians to continue down this road could hold severe implications for the freedom of all people to decide what is right for their own body.” Tennessee claims that their ban on gender-affirming care does not discriminate on the basis of sex even though it bans minors of one sex from accessing health care it allows to members of another sex. A transgender girl is barred from taking doctor-prescribed estrogen because Tennessee considers it “inconsistent” with her birth-assigned sex of male but a cisgender girl with a birth-assigned sex of female is permitted to take estrogen for any purpose including to affirm her female gender identity. “Since this Project’s founding by Justice Ruth Bader Ginsburg, we have adamantly challenged efforts to limit who we can be based on our gender or ability to bear children,” said Ria Tabacco Mar, director of the ACLU’s Women’s Rights Project. “Tennessee’s attempt to limit who young people can become based on their sex shares a through-line with our nation’s history of subjugating women in the name of biology. The fight for each of us to live fully and authentically must include trans people. There is no ‘transgender’ exception to the U.S. Constitution.” In April 2023, the American Civil Liberties Union, the ACLU of Tennessee, Lambda Legal, and Akin Gump Strauss Hauer & Feld LLP sued the state of Tennessee to block S.B. 1, which prohibits medical providers from prescribing medical treatments to transgender youth, such as puberty blockers and hormone replacement therapies, that it exempts for minors who are not transgender. Following a decision by the Sixth Circuit Court of Appeals, S.B. 1 took effect in July 2023. Since 2021, 24 states have banned hormone therapies for transgender youth. “Laws like Tennessee’s are not benign regulations of medical care; they are discriminatory efforts to exclude transgender people from the protections of the Constitution,” said Chase Strangio, co-director of the ACLU’s LGBTQ & HIV Project. “These bans represent a dangerous and discriminatory affront to the well-being of transgender youth across the country and their constitutional right to equal protection under the law.”